# PSO 알고리즘 구현 및 새로운 시도
pso 알고리즘을 사용하여 새로운 학습 방법을 찾는중 입니다
병렬처리로 사용하는 논문을 찾아보았지만 이보다 더 좋은 방법이 있을 것 같아서 찾아보고 있습니다 - A Distribute Deep Learning System Using PSO Algorithm.pdf
기본 pso 알고리즘의 수식은 다음과 같습니다
> $$V_{id(t+1)} = W_{V_id(t)} + c_1 * r_1 (p_{id(t)} - x_{id(t)}) + c_2 * r_2(p_{gd(t)} - x_{id(t)})$$
다음 속도을 구하는 수식입니다
> $$x_{id(t+1)} = x_{id(t)} + V_{id(t+1)}$$
다음 위치를 구하는 수식입니다
> $$
p_{id(t+1)} =
\begin{cases}
x_{id(t+1)} & \text{if } f(x_{id(t+1)}) < f(p_{id(t)})\\
p_{id(t)} & \text{otherwise}
\end{cases}
$$
### 위치를 현재 전역해로 변경(덮어쓰기)하면 안되는 이유
위치를 가장 최적값으로 변경하면 지역 최적값에서 벗어나지 못합니다. 따라서 전역 최적값을 찾을 수 없습니다.
# 초기 세팅
``` shell
conda env create -f env.yaml
```
# 현재 진행 상황
## 1. PSO 알고리즘 구현
### 파일 구조
``` plain text
|-- metacode # pso 기본 코드
| |-- pso_bp.py # 오차역전파 함수를 최적화하는 PSO 알고리즘 구현 - 성능이 99% 이상으로 나오나 목적과 다름
| |-- pso_meta.py # PSO 기본 알고리즘 구현
| |-- pso_tf.py # tensorflow 모델을 이용가능한 PSO 알고리즘 구현
|-- pso # tensorflow 모델을 학습하기 위해 기본 pso 코드에서 수정 - (psokeras 코드 의 구조를 사용하여 만듬)
| |-- __init__.py # pso 모듈을 사용하기 위한 초기화 파일
| |-- optimizer.py # pso 알고리즘 이용을 위한 기본 코드
| |-- particle.py # 각 파티클의 정보 및 위치를 저장하는 코드
|-- psokeras # keras 모델을 이용가능한 PSO 알고리즘 - 다른 사람의 코드
| |-- ***
|-- pyswarms # pyswarms 라이브러리를 이용가능한 PSO 알고리즘 - 다른 사람의 코드
| |-- ***
|-- examples.py # psokeras 코드를 이용한 예제
|-- iris.py # pso 코드를 이용한 iris 문제 풀이
|-- mnist.py # pso 코드를 이용한 mnist 문제 풀이
|-- xor.ipynb # pso 코드를 이용한 xor 문제 풀이
|-- plt.ipynb # pyplot 으로 학습 결과를 그래프로 표현
```
psokeras 및 pyswarms 라이브러리는 외부 라이브러리이기에 코드를 수정하지 않았습니다
pso 라이브러리는 tensorflow 모델을 학습하기 위해 기본 ./metacode/pso_meta.py 코드에서 수정하였습니다
## 2. PSO 알고리즘을 이용한 최적화 문제 풀이
pso 알고리즘을 이용하여 오차역전파 함수를 최적화 하는 방법을 찾는 중입니다
### 브레인스토밍
> 1. 오차역전파 함수를 1~5회 실행하여 오차를 구합니다
> 2. 오차가 가장 적은 다른 노드(particle) 가중치로 유도합니다.
>
>> 2-1. 만약 오차가 가장 작은 다른 노드가 현재 노드보다 오차가 크다면, 현재 노드의 가중치를 유지합니다. - 현재의 가중치를 최적값으로 업로드합니다
>>
>> 2-2. 지역 최적값을 찾았다면, 전역 최적값을 찾을 때까지 1~2 과정을 반복합니다
>
> 3. 전역 최적값이 특정 임계치에서 변화율이 적다면 학습을 종료합니다 - 현재 결과가 정확도가 높지 않아서 이 기능은 추후에 추가할 예정입니다
위의 아이디어는 원래의 목표와 다른 방향으로 가고 있습니다. 따라서 다른 방법을 모색해야할 것 같습니다
## 3. PSO 알고리즘을 이용하여 풀이한 문제들의 정확도
### 1. xor 문제
``` python
loss = 'mean_squared_error'
pso_xor = Optimizer(
model,
loss=loss,
n_particles=75,
c0=0.35,
c1=0.8,
w_min=0.6,
w_max=1.2,
negative_swarm=0.25
)
best_score = pso_xor.fit(
x_test,
y_test,
epochs=200,
save=True,
save_path="./result/xor",
renewal="acc",
empirical_balance=False,
Dispersion=False,
check_point=25
)
```
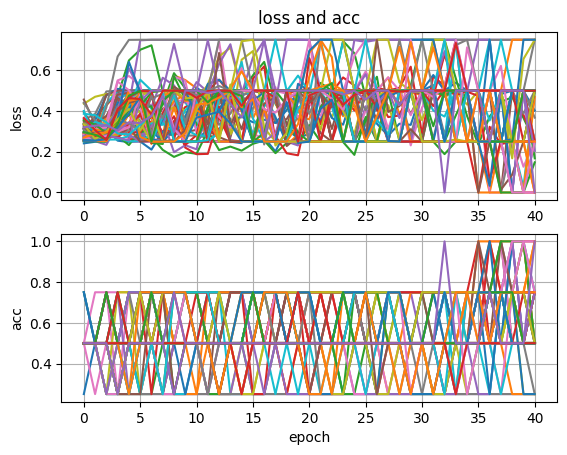
위의 파라미터 기준 40 세대 이후부터 정확도가 100%가 나오는 것을 확인하였습니다
2. iris 문제
``` python
loss = 'categorical_crossentropy'
pso_iris = Optimizer(
model,
loss=loss,
n_particles=50,
c0=0.4,
c1=0.8,
w_min=0.7,
w_max=1.0,
negative_swarm=0.2
)
best_score = pso_iris.fit(
x_train,
y_train,
epochs=200,
save=True,
save_path="./result/iris",
renewal="acc",
empirical_balance=False,
Dispersion=False,
check_point=25
)
```
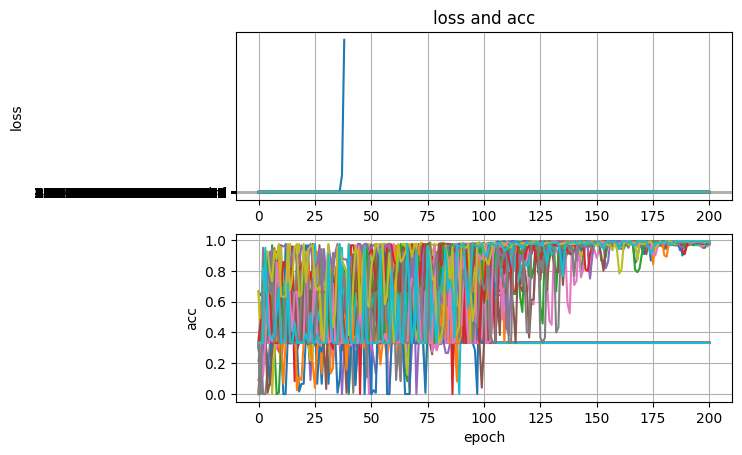
위의 파라미터 기준 2 세대에 94%의 정확도를, 7 세대에 96%, 106 세대에 99.16%의 정확도를 보였습니다
3. mnist 문제
``` python
loss = 'mean_squared_error'
pso_mnist = Optimizer(
model,
loss=loss,
n_particles=50,
c0=0.35,
c1=0.8,
w_min=0.7,
w_max=1.0,
negative_swarm=0.25
)
best_score = pso_mnist.fit(
x_test,
y_test,
epochs=200,
save=True,
save_path="./result/mnist",
renewal="acc",
empirical_balance=False,
Dispersion=False,
check_point=25
)
```
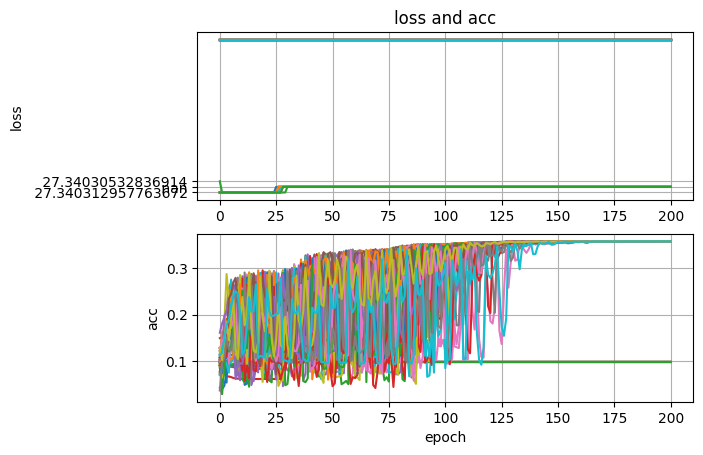
위의 파라미터 기준 현재 정확도 38%를 보이고 있습니다
### Trouble Shooting
> 1. 딥러닝 알고리즘 특성상 weights는 처음 컴파일시 무작위하게 생성된다. weights의 각 지점의 중요도는 매번 무작위로 정해지기에 전역 최적값으로 찾아갈 때 값이 높은 loss를 향해서 상승하는 현상이 나타난다.
> 따라서 weights의 이동 방법을 더 탐구하거나, weights를 초기화 할때 random 중요도를 좀더 노이즈가 적게 생성하는 방향을 모색해야할 것 같다.
-> 고르게 초기화 하기 위해 np.random.uniform 함수를 사용하였습니다
> 2. 지역최적값에 계속 머무르는 조기 수렴 현상이 나타난다. - 30% 정도의 정확도를 가진다
### 개인적인 생각
> 머신러닝 분류 방식에 존재하는 random forest 방식을 이용하여, 오차역전파 함수를 최적화 하는 방법이 있을것 같습니다
>
> > pso 와 random forest 방식이 매우 유사하다고 생각하여 학습할 때 뿐만 아니라 예측 할 때도 이러한 방식으로 사용할 수 있을 것 같습니다
# 참고 자료
> A partilce swarm optimization algorithm with empirical balance stategy -
> psokeras -
> PSO의 다양한 영역 탐색과
지역적 미니멈 인식을 위한 전략 -
> PC 클러스터 기반의 Multi-HPSO를 이용한 안전도 제약의 경제 급전 -
> Particle 2-Swarm Optimization for Robust Search -